关注我的公众号:CoreMarketXin 硬核马克🤓
记得在很早的时候,一个在大厂运营朋友跟我说,他们正在全员学SQL。不过等到我后来进入大厂,依然发现没多少人掌握了SQL。当然这跟团队也有关系,我呆过服务、业务运营团队,以及产品团队,从比例上来说,运营团队的SQL掌握率远低于产品团队。但是从业务本身来说,会SQL对于业务的影响和帮助远大于对产品本身的帮助。
我这里简单梳理一些基础的SQL语法,主要是分享,让更多的运营小伙伴认识SQL。以下是以我业务视角,业务语言,对业务同学的输出,从专业性上肯定不及数据同学的解释,但是更多会关注业务同学需要关注的场景。针对一些复杂的场景,欢迎一起提升学习。
认识SQL:
提到SQL,我们紧接着蹦出口的下一句便是“增删查改”,其实对于运营来说,一般只用到“查”这一个基础场景。对于数据表的增、删、改是BI或者数据科学的同事在做的工作。
要认识SQL,我们先要知道数据在哪里,再讨论怎么查。
比如我们要查询商城的用户id明细,先需要知道这个“id”的字段存储在哪里。一般会有一张业务层的表,我习惯称之为“底表”,即这张表存储了很多的相关字段,比如有id,注册时间,用户昵称等等。
这张表一般需要去公司的数据地图查询(不同公司称呼不同,可以问下数据同事),先找到这张表,申请查询权限,注意查询权限可能不包含部分敏感字段的权限,需要单独申请。
我们就拿上面的实例简单展开:
表的格式一般为:
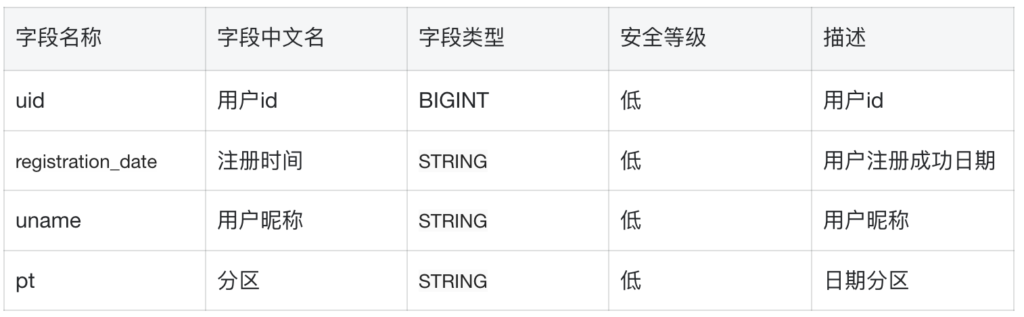
字段存储的基本逻辑为:
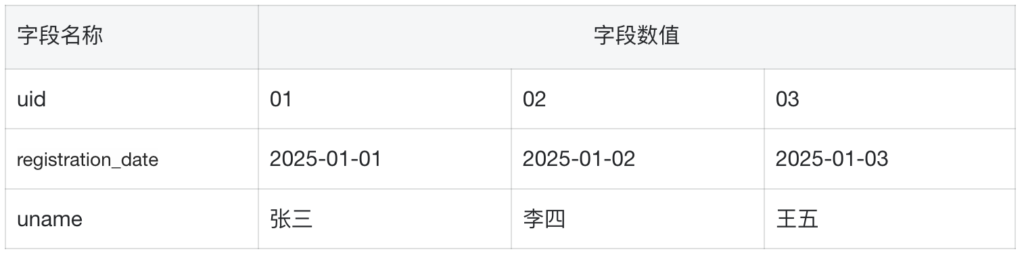
假如我们命名这张表的名称:user_info_1
以上大致能让我们了解到了从哪里可以找到这个字段的问题。接下来我们要讨论,怎么把这个数取出来。
结构:
基础查询:
查询数据的语法结构,至少从我目前的实际工作情况来说,就一种结构。不过根据语言不同稍有不同(比如presto和MySQL)。大体上是一致的。
比如我们要查询上述表中的基础信息,我们可以使用下列方式查询:
select
uid
,uname
,registration_date
from user_info_1
where pt='20250105'最终输出的结果即为在表user_info_1中,最新分区“20250105”存储的所有用户的三个字段的信息。
如果我们要找固定的一个用户他的基础信息,那么可以设定其中的uid条件,如下:
select
uid
,uname
,registration_date
from user_info_1
where pt='20250105'
and uid=01最终输出的就是uid为01的用户的基础信息。
我们在分析业务数据的时候,根据明细,结合Excel的一些统计工具,可以快速找到数据并得出一些初步的业务结论。
关联查询
有了上面基础查询的基础,实际工作中还会经常遇到多表关联:不同的字段在不同的表中,需要关联多表来输出一份完整数据。当然也可以分别查询之后,通过Excel中VLOOKUP工具进行统计,不过这个很麻烦,不如一步到位:相当于我们在sql中直接使用了VLOOKUP函数。
如何进行多表关联?我们先认识一下多表关联需要用到的一个新语法:inner join(内关联),left join(左关联),right join(右关联)。在实际工作中,没用到过inner join。而判断使用left 还是right 关联,首先需要判断最终输出的表的核心字段是左表还是右表。
比如上面有一张用户基础表:user_info_1,我们再找一张用户访问表,命名为:user_info_2,如下:
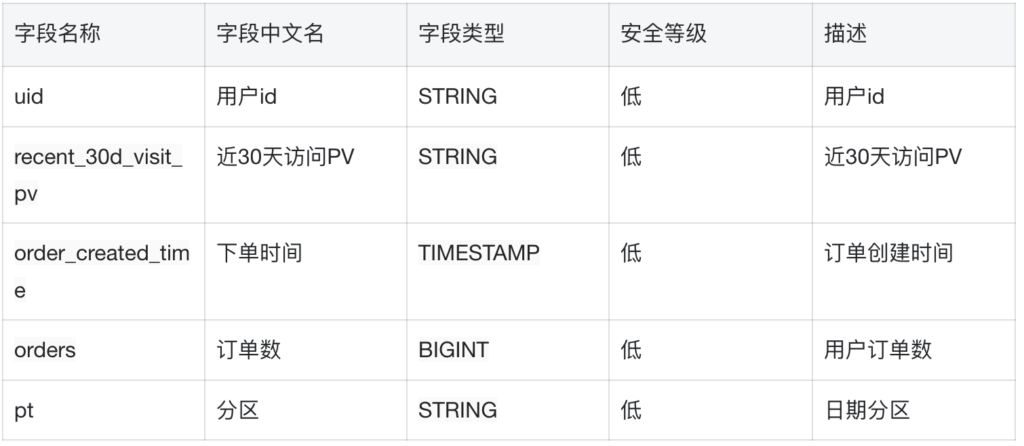
我们要最终输出一份包含用户基础信息以及近30天访问PV的数据,那么就可以这么写:
select
a.uid
,a.uname
,a.registration_date
,b.recent_30d_visit_pv
from
user_info_1 a
left join user_info_2 b
on cast(a.uid as varchar)=b.uid
where pt='20250105'最终输出的就是包含用户基础信息以及近30天访问PV的数据表。同上,如果要查询用户01的数据,叠加一个and的筛选条件即可。
这里的关键点是:
- 两张表需要有一个相同的意义的字段,如上的例子中就是uid,通过uid来关联两张表。
- 不同的表在最后需要加上字符区分,我这里用了“a”,“b”,当然也可以用其他的,只要能区分开就可以
- 在不同的表中的字段,要与表末带的字符一致,都需要加上对应的字符,如“a.uid”,“b.recent_30d_visit_pv”
特殊语法:
除了上述的几个基础查询语句,在实际工作中还有几个比较实用的语法。能帮助运营提升查询效率。
sum:聚合函数。用于计算某一字段的和。这个可以直接类比Excel中的sum函数。
例:最终输出的结果就是订单数量之和。
select sum(orders)
from user_info_2
where pt='20250105'count:计数函数。用于统计某个字段的非空的数量。
distinct:去重,返回的是去重的字段明细。
上述两个函数一般来说会结合起来用,例:最终输出的是平台去重的用户数量:
select count(distinct uid)
from user_info_1
where pt='20250105'时间取值:通过限制时间或者时间周期,来看某一(段)时间内的数值表现情况。
例:最终输出的就是这个时间(段)内的数据情况。
select
uid
,order_created_time
,orders
from user_info_2
where pt='20250105'
AND substr(CAST(a.gmt_created_time AS VARCHAR),1,7) = '2024-06'
--AND substr(CAST(a.gmt_created_time AS VARCHAR),1,10) >= '2024-06-28' and substr(CAST(a.gmt_created_time AS VARCHAR),1,10) <= '2024-07-04'
--AND substr(CAST(a.gmt_created_time AS VARCHAR),1,7) >= '2024-01' and substr(CAST(a.gmt_created_time AS VARCHAR),1,7) <= '2024-07'顺便提一下,字段前“–”表示不运行该语句。方便我们快速定位语法问题,或者添加备注。当然有的也写作“/*”表达的意思是一致的。
另外两个也经常用,但是就不举例了,大家可以自己手动尝试下。
group by:用于将数据按指定的字段分组,通常与聚合函数一起使用。
limit:限制查询结果的数量。
注意点:
这里还有一个需要注意的小知识点,当使用关联函数join或者条件函数(and,where)的时候,我们需要关注这个字段的字符类型:varchar(string) 字符型,需要加单引号,bigint数值型/整型,不要加引号。
例如上面这个例子:
select
uid
,uname
,registration_date
from user_info_1
where pt='20250105'
and uid=01uid属于数值型(BIGINT),pt就属于字符型(STRING),所以在书写上有所不同。
另一个是当使用关联函数,用a表的字段去映射b表的时候,如果a表的字符是BIGINT,需要先将BIGINT通过cast函数转化为STRING,如下:
on cast(a.uid as varchar)=b.uid结语:
sql要深入很难,我在实际工作中也是用到了一些基础的语法,但是这些语法帮助我大大提升了效率,缓和了与数据同事的职场关系(至少是省了大把的提交、等待数据需求的时间,以及帮数据同学减少了大把查询数据的时间。)
另外,学习sql还需要掌握这几点:
1.刻意练习,不断重复使用,提升熟练度
2.保持好奇心,不断学习新的语法
3.厚脸皮,总有遇到不会的,要多问,并且不懂就问
4.最后还推荐大家一个工具:kimi,实在找不到人问问题的情况下,可以问问AI。
转载请注明:硬核马克 » 提升职场竞争力,运营必须要会SQL